模拟数据生成器:原理解析
Written By

技能练习生
你可能想知道,为什么这个工具生成的提问听起来那么像真人,而不是干巴巴的指令?这得益于它背后的一套“积木式”生产逻辑。
核心工作流
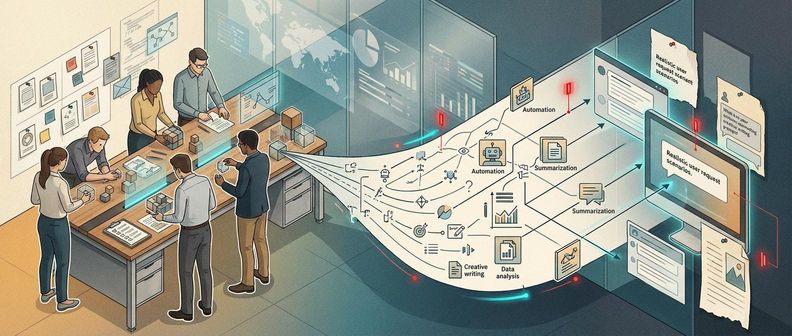
下面的流程展示了数据是如何从一个想法变成一条真实的测试题的:
为什么这样做更有效?
从“变量”而非“句子”开始
如果让 AI 直接写 100 句提问,它往往在大约 10 句之后就开始自我重复。我们强制系统先处理“变量组合”(比如先把人设、场景、清晰度配好),就像先搭好积木的骨架,每一块积木的颜色和形状都被提前预定了,这样能保证产出的数据具有极高的多样性。
“两步走”翻译法
为了让生成的句子不带“AI 味”,系统不会在生成变量时就顺便写句子。我们会把“定义意图”和“自然语言改写”拆开,模拟真人在特定情境下的表达习惯。这就像是先想好“我要投诉”,再根据“我很着急”这个设定,把它改写成一句带情绪的话。
分层抽样的智慧
当系统处理真实数据时,它不是盲目采样。它会先通过一种叫“聚类”的技术,把现有的数据分成不同的堆。如果发现某一堆数据特别少(比如冷门的报错咨询),它就会重点在这个领域进行模拟,帮你把测试集的“短板”补齐。
数据安全与隐私
该 Skill 在处理你的真实数据采样时,仅对 queries 的统计特征进行分析。我们建议在上传真实数据前,先将涉及个人身份、公司机密等敏感信息进行去隐私处理。